新闻速览
2025 年 5 月 23 日,Anthropic 于 正式推出 Claude Opus 4 和 Claude Sonnet 4 两款全新大模型,号称连续7小时编程,世界上最强大的编程模型,究竟有何特别之处呢?

技术优势
在 SWE-bench 测试中,Opus 4 和 Sonnet 4 都表现出色,准确率分别为 79.4% 和 80.2%,这显示了它们在解决复杂编程问题时的强大能力。此外,在 Terminal-bench 测试中,Opus 4 以 43.2% 的准确率领先,显示出它在处理长时间命令行任务时的优势,而 Sonnet 4 则以 35.5% 的成绩表现稳定,适合日常开发中的常见命令行操作。
什么是 SWE-bench 和 Terminal-bench 测试?
SWE-bench 测试:主要用于评估模型在编程和软件开发任务中的能力。这些任务通常涉及修改和调试代码,测试模型能否理解问题并修复代码。它来源于多个Github开源项目,测试的是模型在解决实际问题时的准确度。
Terminal-bench 测试:这个测试评估模型在命令行界面下的表现,特别是处理需要执行多个命令或长时间运行的任务的能力。命令行操作在软件开发中非常常见,因此测试模型在此环境中的表现非常重要。
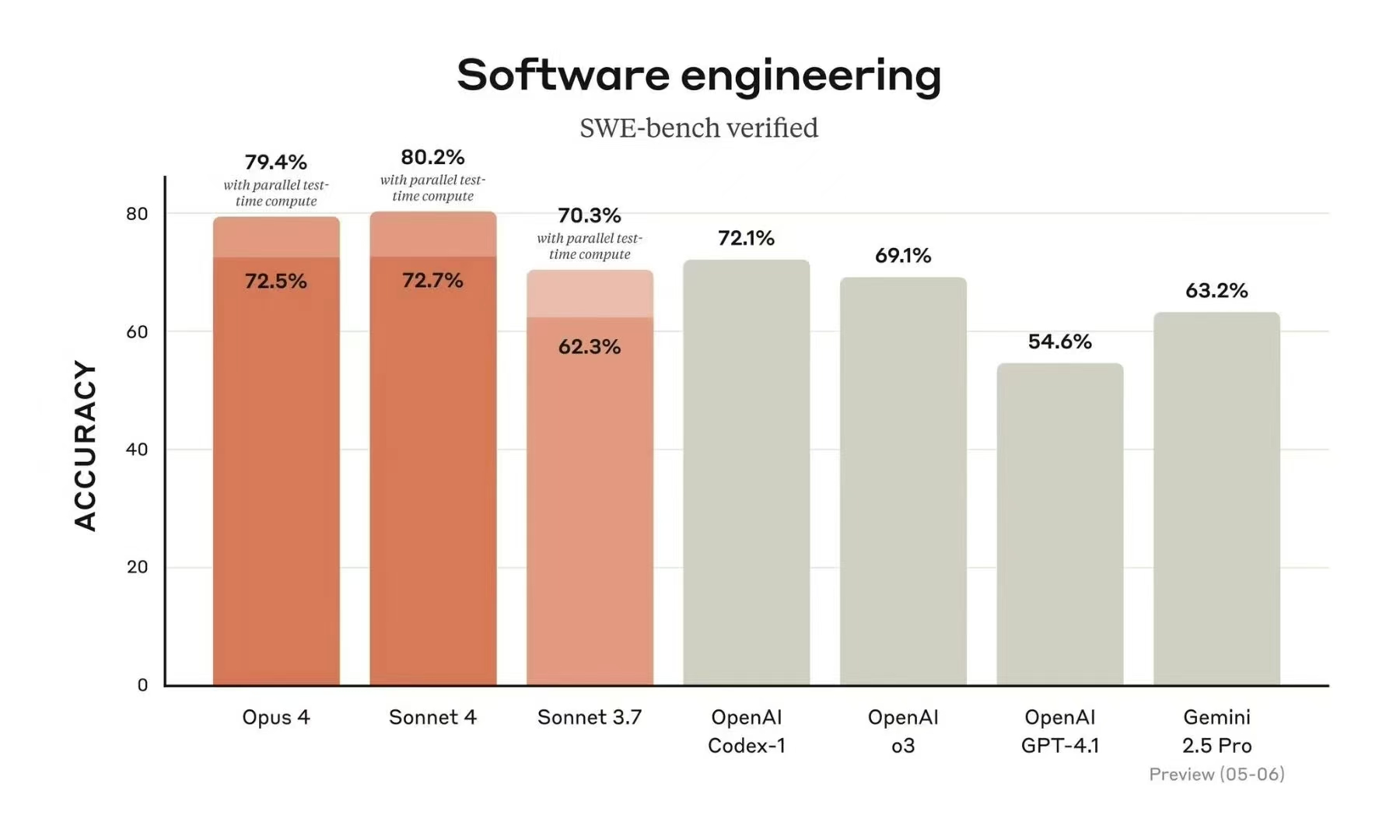
再看看官网公布的另一份数据
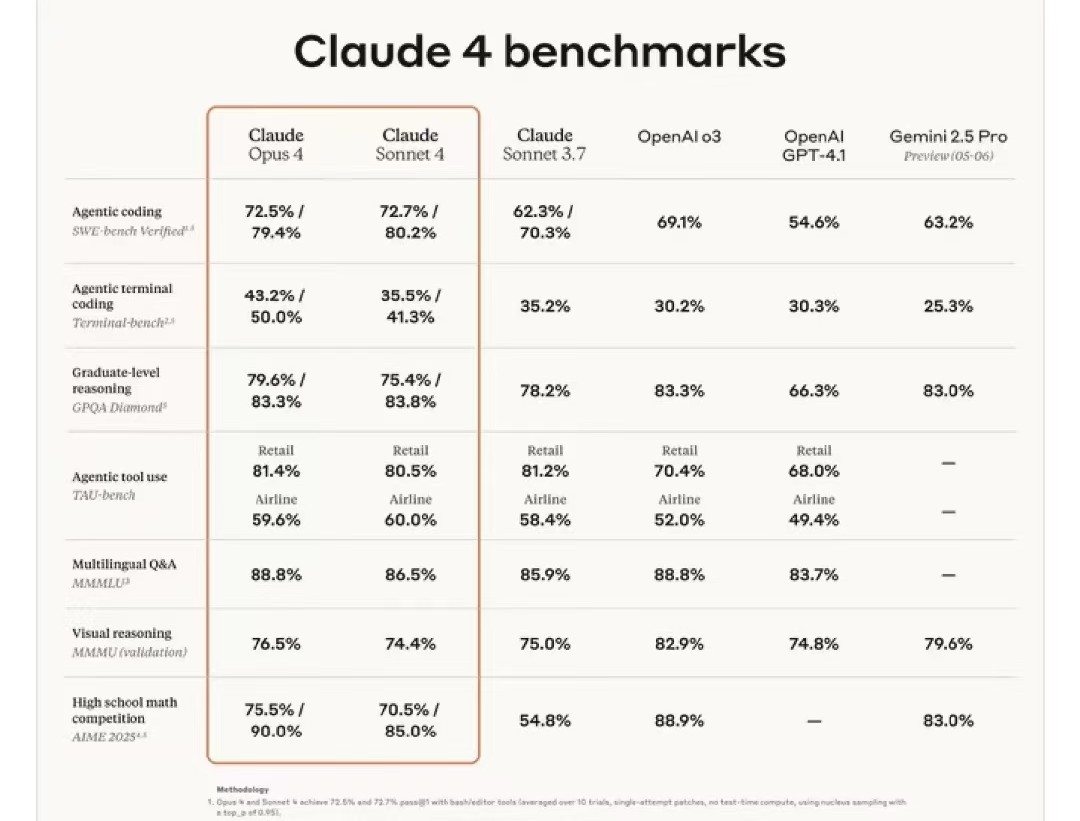
Agnetic coding(编程任务)和Agnetic terminal coding(命令行编程)上述已介绍过,不再赘述。
Graduate-level reasoning(高级推理能力): Claude Opus 4 在推理任务中也表现强劲,准确率为 83.3%,明显优于其他模型。
Multilingual Q&A(多语言问答):Claude Opus 4 在多语言问答任务中表现出色,准确率为 88.8%。
Visual reasoning(视觉推理): 在视觉推理任务中,Claude Sonnet 4 的表现为 75.4%,在与其他模型的对比中也显示出了较强的能力。
适合谁用?
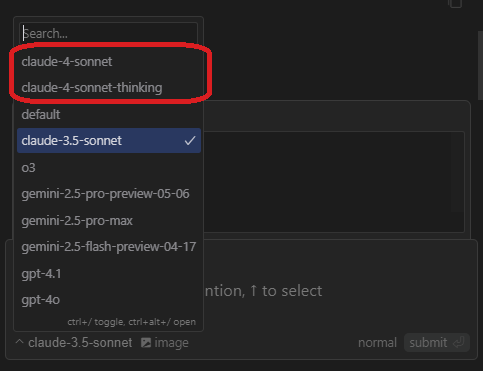
其实Claude的适用人群早已贴合清晰。强大的编程能力和推理能力,是最适合开发者使用的AI工具,而就在今天,著名的AI编程IDE-Cursor已经急速适配了最新的Claude模型。
不过笔者需要提醒各位朋友,目前简单的测试已经很难清晰的检测出不同的AI模型的区别,在Claude3.5的时代写写管理系统是较为轻松的,如今也仍然如此,可拉开模型差距的一定是愈加复杂,贴合生产实际的开发,因此如果您没有较为实际的生产需求,可能还不能立刻感受到Claude4的魅力,但倘若您是借助Claude开发复杂的生产程序,它的无与伦比才会真正显现出来。
笔者提一嘴,著名的windsurf倒是没跟上这一波节奏,还未适配最新的开发模型。
结语
Claude4的出现,意味着AI编程的进一步腾飞,想要跟上时代,了解更多Claude或者AI编程信息的朋友,可以关注公众号:AI猫学长,获取最新资讯。
最近笔者打算写写如何利用Cursor实现轻松的赚钱,唯一的要求是您学习过程序开发,即使没有项目没有技术也没有关系,主要是对这一行有基本的了解,大部分工作都是AI完成,有兴趣的朋友可以关注一下公众号。

本文由 AI猫学长 原创,采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。



